1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
| import json
import pandas as pd
import torch
from datasets import Dataset
from modelscope import snapshot_download, AutoTokenizer
from transformers import AutoModelForCausalLM, TrainingArguments, Trainer, DataCollatorForSeq2Seq
import os
import swanlab
os.environ["SWANLAB_PROJECT"] = "qwen3-sft-k12"
PROMPT = "你是一位K12教育销售专家,专注于为掌门教育提供家长沟通解决方案。"
MAX_LENGTH = 2048
swanlab.config.update({
"model": "Qwen/Qwen3-1.7B",
"prompt": PROMPT,
"data_max_length": MAX_LENGTH,
})
def dataset_jsonl_transfer(origin_path, new_path):
"""
将原始数据集转换为大模型微调所需数据格式的新数据集
"""
messages = []
with open(origin_path, "r") as file:
for line in file:
data = json.loads(line)
input = f"{data['question']}"
output = f"话术:{data['answer']}"
message = {
"instruction": PROMPT,
"input": f"{input}",
"output": output,
}
messages.append(message)
with open(new_path, "w", encoding="utf-8") as file:
for message in messages:
file.write(json.dumps(message, ensure_ascii=False) + "\n")
def process_func(example):
"""
将数据集进行预处理
"""
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(
f"<|im_start|>system\n{PROMPT}<|im_end|>\n<|im_start|>user\n{example['input']}<|im_end|>\n<|im_start|>assistant\n",
add_special_tokens=False,
)
response = tokenizer(f"{example['output']}", add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = (
instruction["attention_mask"] + response["attention_mask"] + [1]
)
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
def predict(messages, model, tokenizer):
device = "cuda"
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=MAX_LENGTH,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
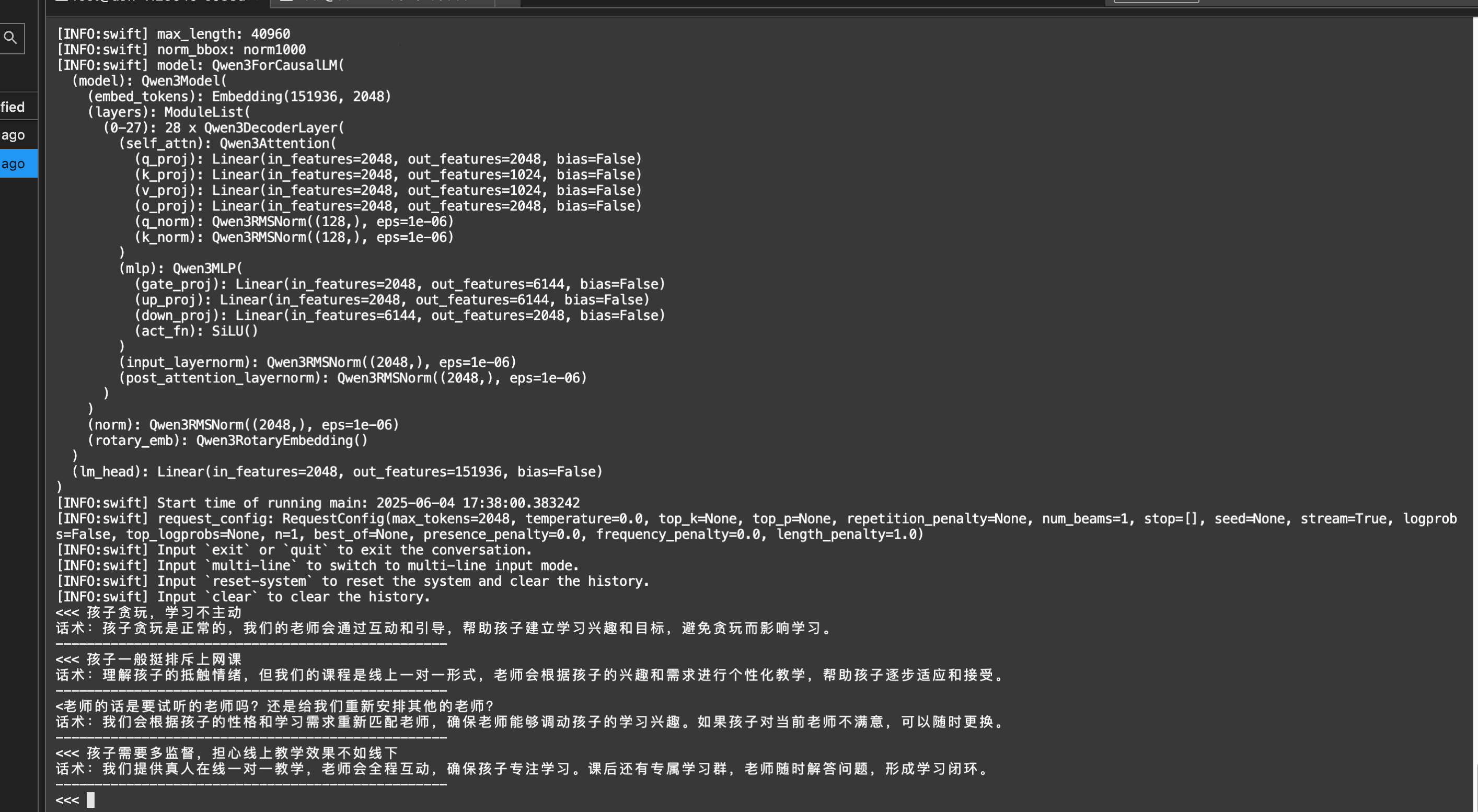
model_dir = snapshot_download("Qwen/Qwen3-1.7B", cache_dir="/root/autodl-tmp/", revision="master")
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/Qwen/Qwen3-1.7B", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("/root/autodl-tmp/Qwen/Qwen3-1.7B",
torch_dtype=torch.bfloat16)
model.enable_input_require_grads()
train_dataset_path = "train.jsonl"
test_dataset_path = "val.jsonl"
train_jsonl_new_path = "train_format.jsonl"
test_jsonl_new_path = "val_format.jsonl"
if not os.path.exists(train_jsonl_new_path):
dataset_jsonl_transfer(train_dataset_path, train_jsonl_new_path)
if not os.path.exists(test_jsonl_new_path):
dataset_jsonl_transfer(test_dataset_path, test_jsonl_new_path)
train_df = pd.read_json(train_jsonl_new_path, lines=True)
train_ds = Dataset.from_pandas(train_df)
train_dataset = train_ds.map(process_func, remove_columns=train_ds.column_names)
eval_df = pd.read_json(test_jsonl_new_path, lines=True)
eval_ds = Dataset.from_pandas(eval_df)
eval_dataset = eval_ds.map(process_func, remove_columns=eval_ds.column_names)
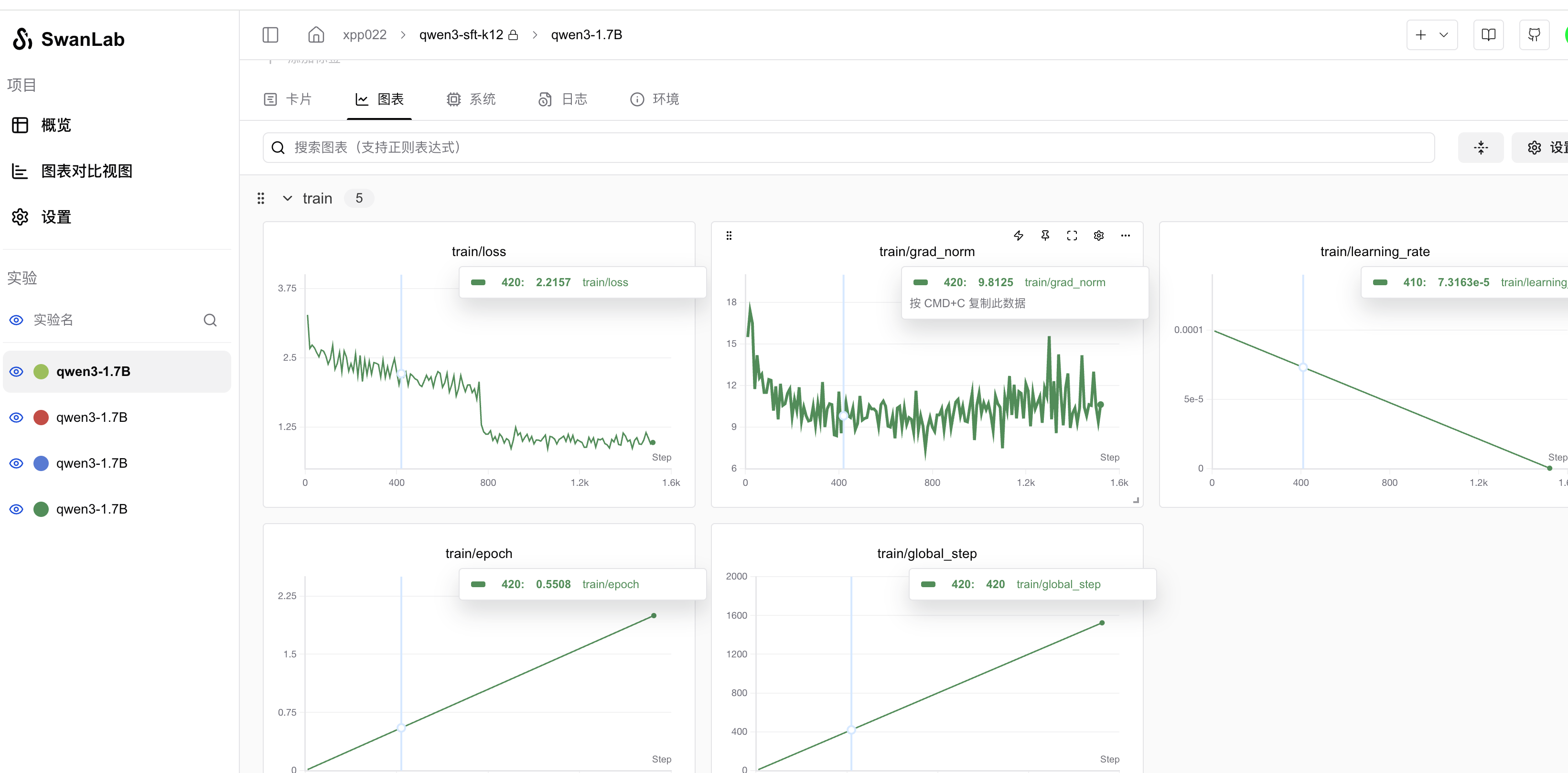
args = TrainingArguments(
output_dir="/root/autodl-tmp/output/Qwen3-1.7B",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=4,
eval_strategy="steps",
eval_steps=100,
logging_steps=10,
num_train_epochs=2,
save_steps=400,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True,
report_to="swanlab",
run_name="qwen3-1.7B",
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
trainer.train()
test_df = pd.read_json(test_jsonl_new_path, lines=True)[:3]
test_text_list = []
for index, row in test_df.iterrows():
instruction = row['instruction']
input_value = row['input']
messages = [
{"role": "system", "content": f"{instruction}"},
{"role": "user", "content": f"{input_value}"}
]
response = predict(messages, model, tokenizer)
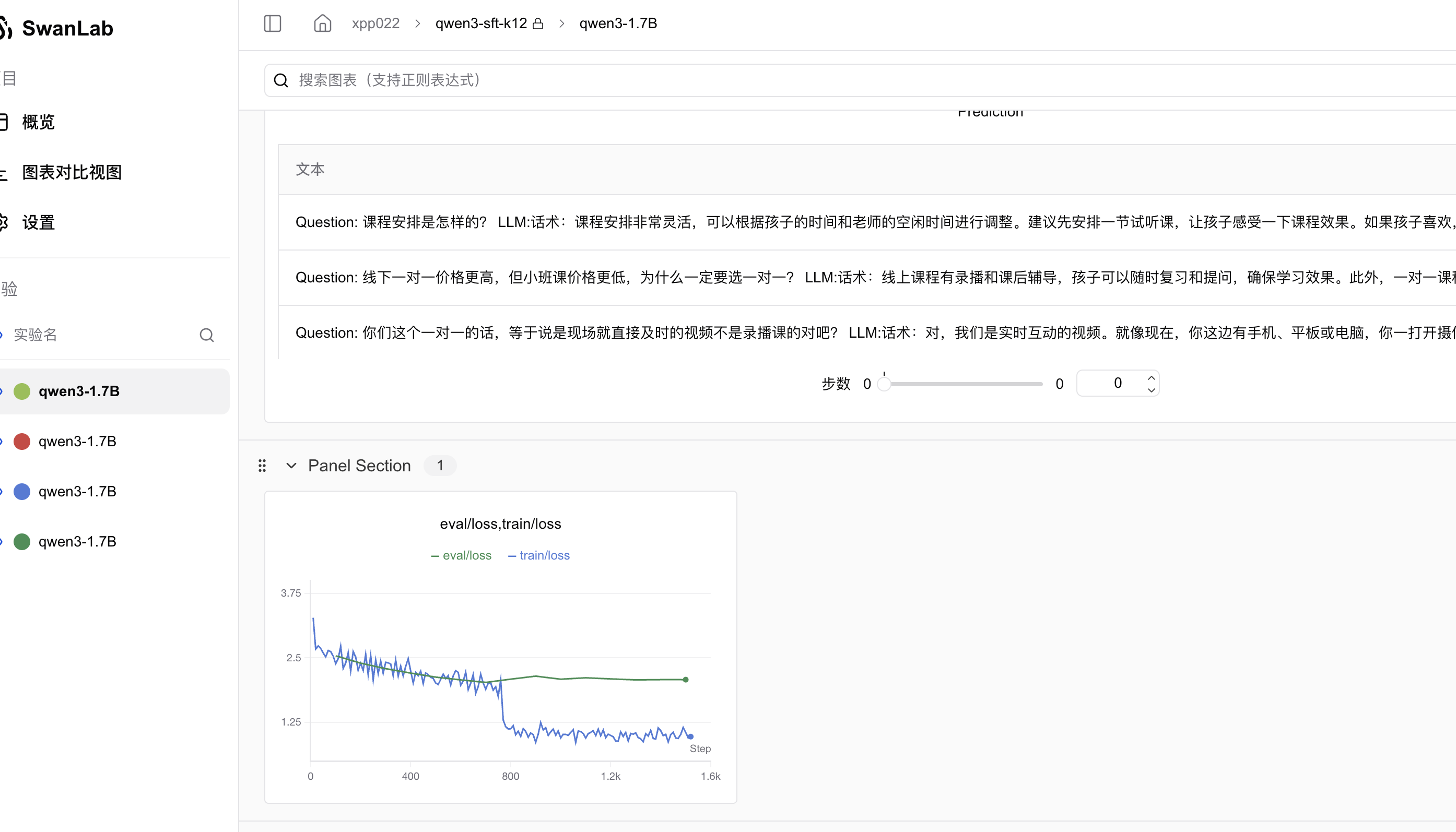
response_text = f"""
Question: {input_value}
LLM:{response}
"""
test_text_list.append(swanlab.Text(response_text))
print(response_text)
swanlab.log({"Prediction": test_text_list})
swanlab.finish()
|